資料內(nèi)容:
一、基于LLM+向量庫的文檔對話 基礎(chǔ)面
1.1 為什么 大模型 需要 外掛(向量)知識庫?
如何 將 外部知識 注入 大模型,最直接的方法:利用外部知識對大模型進(jìn)行微調(diào)
既然 大模型微調(diào) 不是 將 外部知識 注入 大模型 的 最優(yōu)方案,那是否有其它可行方案?
1.2. 基于LLM+向量庫的文檔對話 思路是怎么樣?
版本一
版本一
• 思路:構(gòu)建幾十萬量級的數(shù)據(jù),然后利用這些數(shù)據(jù) 對大模型進(jìn)行微調(diào),以將 額外知識注入大模型
• 優(yōu)點(diǎn):簡單粗暴
• 缺點(diǎn):
i. 這 幾十萬量級的數(shù)據(jù) 并不能很好的將額外知識注入大模型;
ii. 訓(xùn)練成本昂貴。不僅需要 多卡并行,還需要 訓(xùn)練很多天;
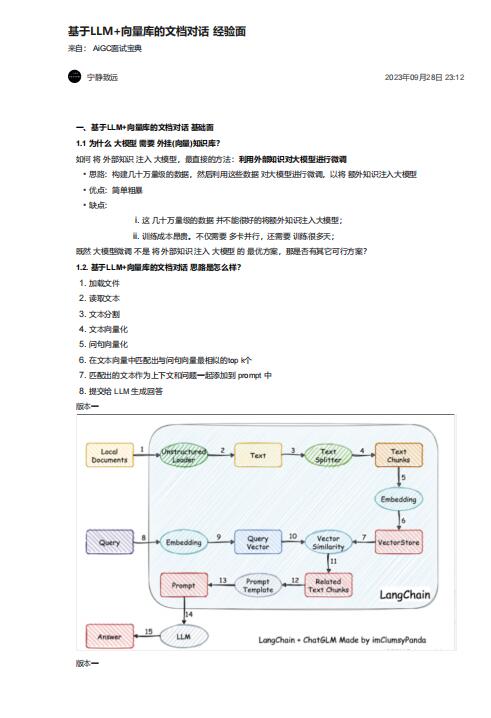
1. 加載文件
2. 讀取文本
3. 文本分割
4. 文本向量化
5. 問句向量化
6. 在文本向量中匹配出與問句向量最相似的top k個
7. 匹配出的文本作為上下文和問題一起添加到 prompt 中
8. 提交給 LLM 生成回答

