資料內(nèi)容:
一、為什么需要進行pdf解析?
最近在探索ChatPDF和ChatDoc等方案的思路,也就是用LLM實現(xiàn)文檔助手。在此記錄一些難題和解決方案,首
先講解主要思想,其次以問題+回答的形式展開。
二、為什么需要 對 pdf 進行解析?
當 利用 LLMs 實現(xiàn)用戶與文檔對話時,首要工作 就是 對 文檔中內(nèi)容 進行 解析 。
由于pdf是最通用,也是最復雜的文檔形式,所以 對 pdf 進行解析 變成 利用LLM實現(xiàn)用戶與文檔對話 的 重中之
重 工作。
如何精確地回答用戶關于文檔的問題,不重也不漏?筆者認為非常重要的一點是文檔內(nèi)容解析。如果內(nèi)容都不能
很好地組織起來,LLM只能瞎編。
三、pdf解析 有哪些方法,對應的區(qū)別是什么?
pdf的解析大體上有兩條路,一條是基于規(guī)則,一條是基于AI。
四、pdf解析 存在哪些問題?
pdf轉(zhuǎn)text這塊存在一定的偏差,尤其是paper中包含了大量的figure和table,以及一些特殊的字符,直接調(diào)用
langchain官方給的pdf解析工具,有一些信息甚至是錯誤的。
這里,一方面可以用arxiv的tex源碼直接抽取內(nèi)容,另一方面,可以嘗試用各種ocr工具來提升表現(xiàn)。
五、如何 長文檔(書籍)中關鍵信息?
對于 長文檔(書籍),如何獲取 其中關鍵信息,并構(gòu)建索引:
• 方法一:基于規(guī)則:
• 介紹:根據(jù)文檔的組織特點去“算”每部分的樣式和內(nèi)容
• 存在問題:不通用,因為pdf的類型、排版實在太多了,沒辦法窮舉
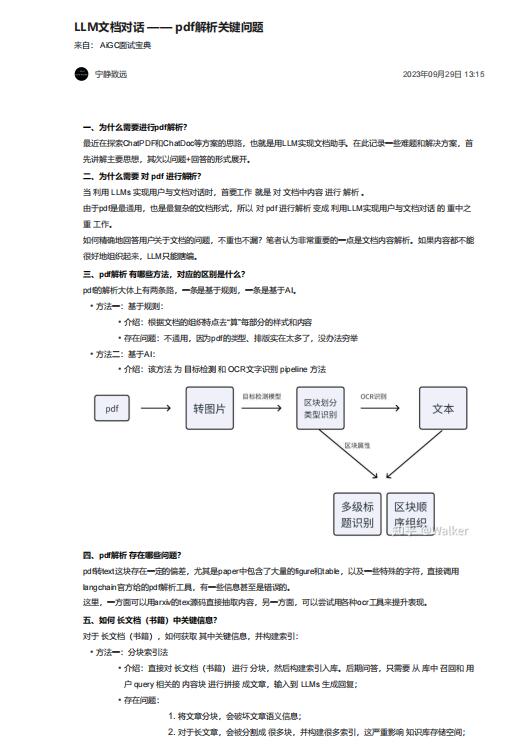
• 方法二:基于AI:
• 介紹:該方法 為 目標檢測 和 OCR文字識別 pipeline 方法

